从ASCII到Unicode,以及UTF-8、UTF-16、UTF-32
Unicode起源#
ASCII#
ASCII(American Standard Code for Information Interchange)是一种字符编码标准,它使用7位二进制数来表示128个字符,包括大小写字母、数字、标点符号、控制字符等。ASCII编码是由美国国家标准协会(ANSI)制定的,于1963年发布,是最早的字符编码标准之一。
ASCII不够用了#
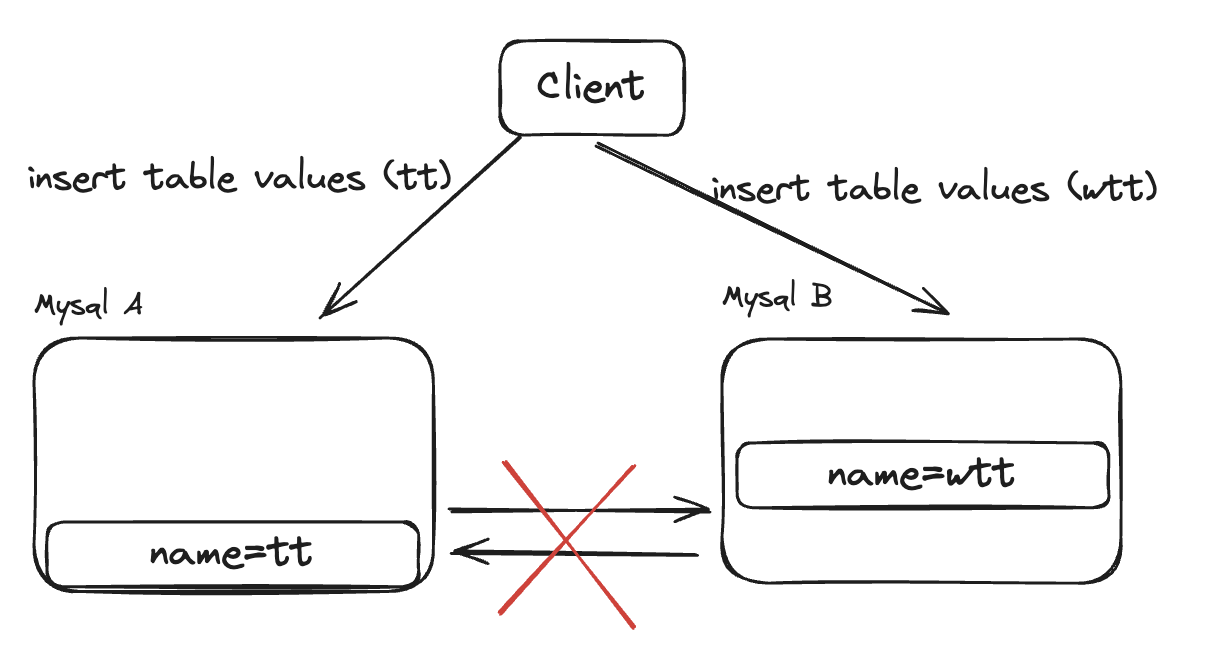
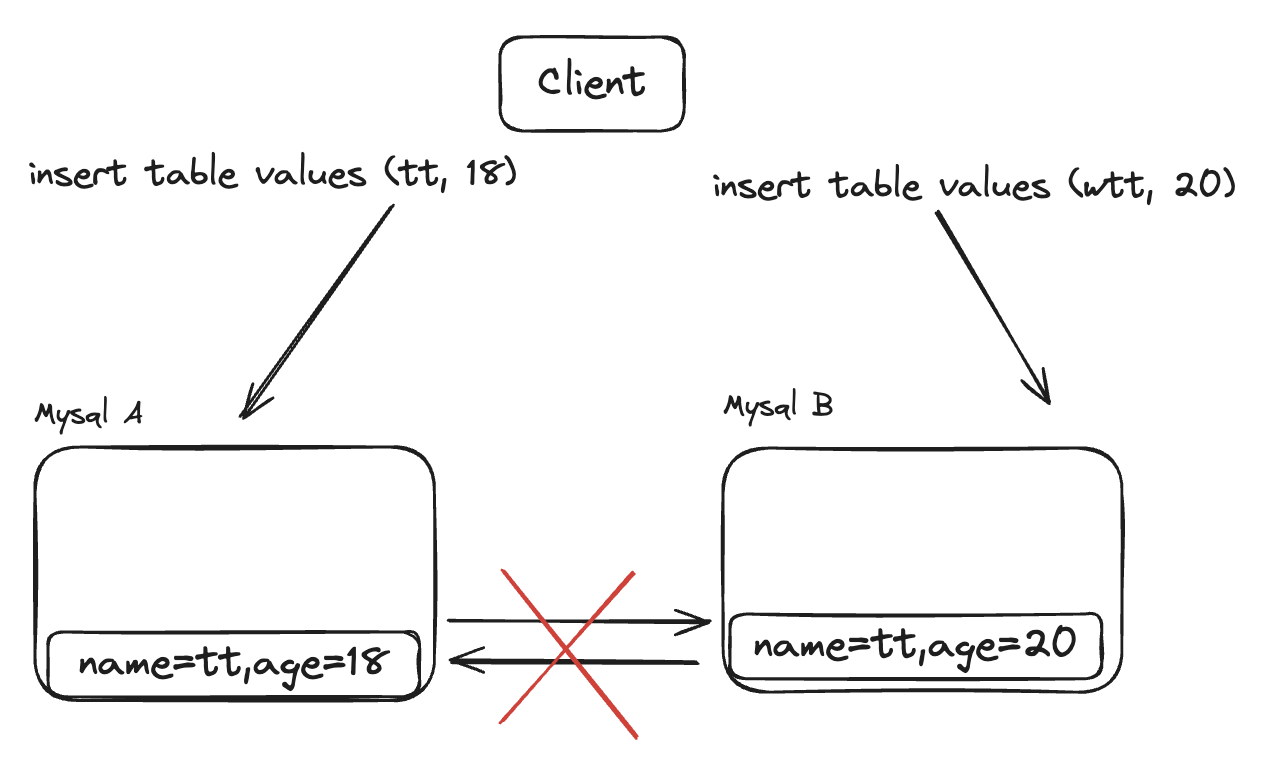
随着计算机不仅仅用于英文,而是用于全球各种语言,ASCII编码已经不能满足需求,针对不同语言的编码方案也应运而生,这其中诞生了很多编码方案,比如GB2312、BIG5、ISO-8859等,这些字符集典型的就是将ASCII的最高位利用起来,将7位扩展到8位,这样就可以表示256个字符。比如ISO-8859-1就是将ASCII的最高位利用起来,表示了拉丁字母。ISO-8859-5表示了西里尔字母。
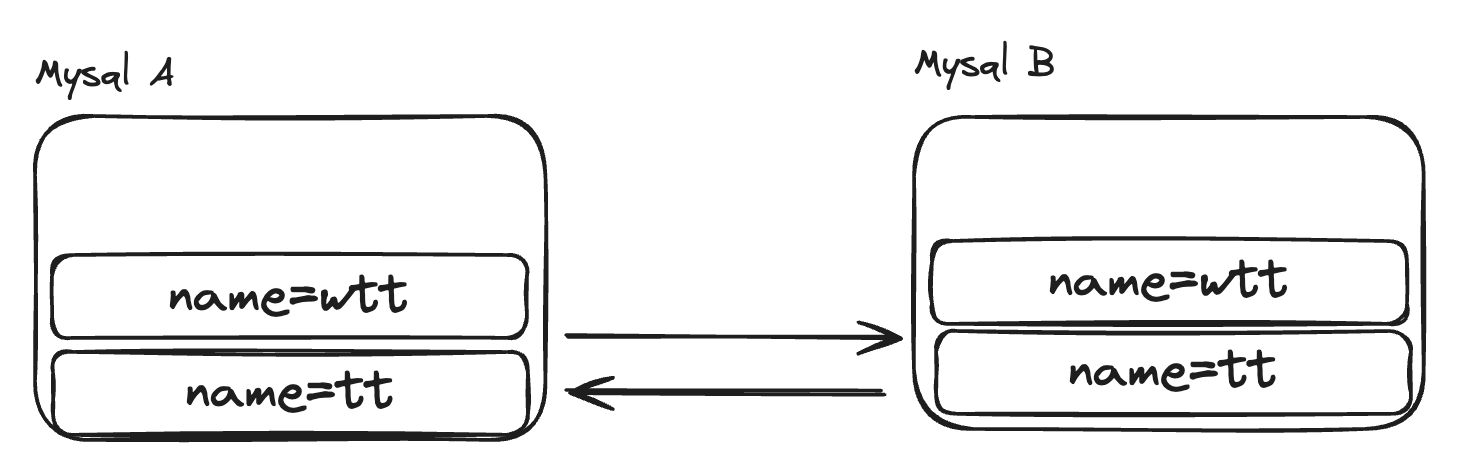
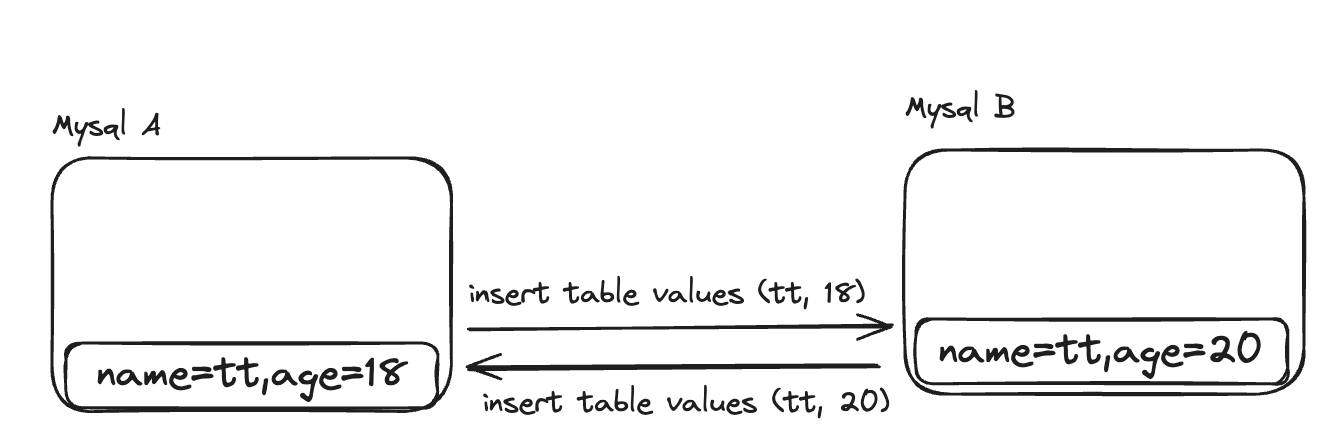
这些字符集各自不包含全部的字符,而且不兼容,这就导致了字符集混乱。这导致在一个文件中混用多种字符成为了不可能完成的事情。而Unicode改变了这一切,它的愿景就是Unicode官网中说到的。
1 | Everyone in the world should be able to use their own language on phones and computers. |
在早期,Unicode曾想过固定使用16位来表示字符,这就是UCS-2编码,也是UTF-16的前身,后面发现固定16位字符还是不够用,这才发展成了我们现在熟知的Unicode。
Unicode介绍#
Unicode是一个文本编码标准。Unicode通过一个唯一的数字来定义每个字符,不管平台、程序或语言。这个数字叫做码点(code point)。Unicode码点是从0x000000到0x10FFFF(十六进制),书写上通常使用U+打头,跟上至少4位十六进制数(不足则补0),如U+0041(字母A)、U+1F600(emoji 😀),理论上,Unicode可以定义1114112个字符。
Unicode的码点跟字符是怎么对应的呢?Unicode将这些码点分成了若干个区段,每个区段称为一个平面(plane),每个平面包含65536(对应低位的0x0000~0xffff)个码点。Unicode总共有17个平面,编号从0到16。Unicode的码点分布如下:
| 平面编号 | 码点区间 | 英文缩写 | 英文名 | 中文名 |
|---|---|---|---|---|
| 0 号平面 | U+000000 - U+00FFFF | BMP | Basic Multilingual Plane | 基本多文种平面 |
| 1 号平面 | U+010000 - U+01FFFF | SMP | Supplementary Multilingual Plane | 多文种补充平面 |
| 2 号平面 | U+020000 - U+02FFFF | SIP | Supplementary Ideographic Plane | 表意文字补充平面 |
| 3 号平面 | U+030000 - U+03FFFF | TIP | Tertiary Ideographic Plane | 表意文字第三平面 |
| 4 号平面 ~ 13 号平面 | U+040000 - U+0DFFFF | / | 已分配,但尚未使用 | / |
| 14 号平面 | U+0E0000 - U+0EFFFF | SSP | Supplementary Special-purpose Plane | 特别用途补充平面 |
| 15 号平面 | U+0F0000 - U+0FFFFF | PUA-A | Private Use Area-A | 保留作为私人使用区 (A区) |
| 16 号平面 | U+100000 - U+10FFFF | PUA-B | Private Use Area-B | 保留作为私人使用区 (B区) |
中文、英文均在0号平面,详细的分配可以参考Unicode的RoadMap。
那么Unicode先定义了码点和字符之间的对应关系,但是如何存储在磁盘上,如何在网络中传输,这就引入了编码方式,编码方式决定了Unicode的码点如何转换为字节流。这就是Unicode定义的三种编码方式:UTF-32、UTF-16、UTF-8。
UTF-32(32-bit Unicode Transformation Format)#
在介绍完Unicode之后,UTF-32是最简单、最容易想到的一种编码方式,直接将Unicode的码点以32位整数的方式存储起来。其中Rust的字符类型char,就使用32位值来表示Unicode字符。
但是这种方式也有很显然的缺点,就是浪费空间,实际Unicode的范围,只需要21位就可以表示了,变长编码就应运而生。
UTF-16(16-bit Unicode Transformation Format)#
这里我想给大家讲一个背景知识,编码方案的扩展,通常会尝试去兼容旧的编码方案,这使得新的编辑器可以打开旧的文件,如果没有用到新的字符,那么新的文件也可以被旧的编辑器打开。这使得演进更加平滑,更易落地。
那就不得不先说一下UCS-2编码方案,如前所述,UCS-2想通过固定16位来表示字符,虽然它最终失败了,但是也影响了很多的系统,比如Windows、Jdk。
UTF-16编码就以兼容UCS-2编码、变长为两个目标,UTF-16的编码规则
- ① 对于码点小于等于U+FFFF的字符,直接使用16位表示,兼容UCS-2
- ② 对于码点小于等于U+10FFFF的字符,使用两个16位表示
对于变长编码来说,对于文件中的任意一个字符,怎么能判断出来这是场景①的字符,还是场景②的第一个字符?抑或是场景②的第二个字符?
Unicode给出的答案是,通过在BMP中舍弃U+D800到U+DFFF的码点,这个区间被称为代理对(surrogate pair),这个区间的码点不会被分配给字符,这样就可以通过这个区间来判断是场景①还是场景②。如果读取的时候,发现前两个字节是D8到DB,那么就是场景②的第一个字符;如果是DC到DF,那么就是场景②的第二个字符;否则就是场景①的字符。
- 高代理(High-half surrogates):范围是0xD800~0xDBFF,二进制范围为1101 1000 0000 ~ 1101 1111 1111,这也代表着高代理的前六位一定是110110。
- 低代理(Low-half surrogates):范围是0xDC00~0xDFFF,二进制范围为1101 1100 0000 ~ 1101 1111 1111,这也代表着低代理的前六位一定是110111。
那么聪明的读者应该分析出来了,使用两个16位表示,由于存在代理对的固定部分,剩余的有效位还剩下20位。这20位恰好可以覆盖从U+010000到U+10FFFF的码点范围。由于U+0000-U+FFFF已经在场景①中覆盖,通过将码点减去0x10000,范围就变成了0x000000~0x0FFFFF,恰好是20位整数。
UTF-8(8-bit Unicode Transformation Format)#
UTF-8的编码规则
- ① 对于码点小于等于U+007F的字符,直接使用8位表示,兼容ASCII。
- ② 对于码点小于等于U+07FF的字符,使用两个8位表示,其中有效位为11位。
- ③ 对于码点小于等于U+FFFF的字符,使用三个8位表示,其中有效位为16位。
- ④ 对于码点小于等于U+10FFFF的字符,使用四个8位表示,其中有效位为21位。
- ⑤ 使用n个字节(n>1)来表示一个字符时,第一个字节的前n位都是1,第n+1位是0,后面的字节的前两位都是10
那么对于一个字节,就可以通过首位是不是1,来判断是1个字节还是n个字节,再通过第二个字节判断是否是首位,最后通过首位来判断字节的个数。
由于UTF-8的有效位最大可达21位,这也就使得UTF-8不用像UTF-16那样减去0x10000。
通过兼容ASCII,最短只用1个字节,这使得UTF-8成为了堪称最流行的编码方式,如果不需要兼容UCS-2,那么几乎可以说UTF-8是最好的选择,堪称当前事实上的标准。值得一提的是,UTF-8的主要设计者,也是Unix的创始人之一,Go语言的设计者之一,Ken Thompson。
扩展知识#
JDK17中英文字符集内存占用量降低了一半#
读者可能会觉得JDK17中中文字符内存占用降低一半是从UTF-16切换到UTF-8导致的,但实则不然,对于JDK来说,切换一种编码方式可谓是伤筋动骨,JDK17通过了JEP254提案,通过添加一个标志位,如果字符串的字符都是ISO-8859-1/Latin-1字符,那么就使用一个字节进行存储。