优雅启停VS重试,谁能更好地保证RPC无损
背景#
我们的业务有些时候总是在升级期间rpc业务有一些呼损,想总结一下让rpc调用零呼损的两种方式:重试和优雅启停。我先介绍这两种方式,再描述一下这两种方式的优缺点
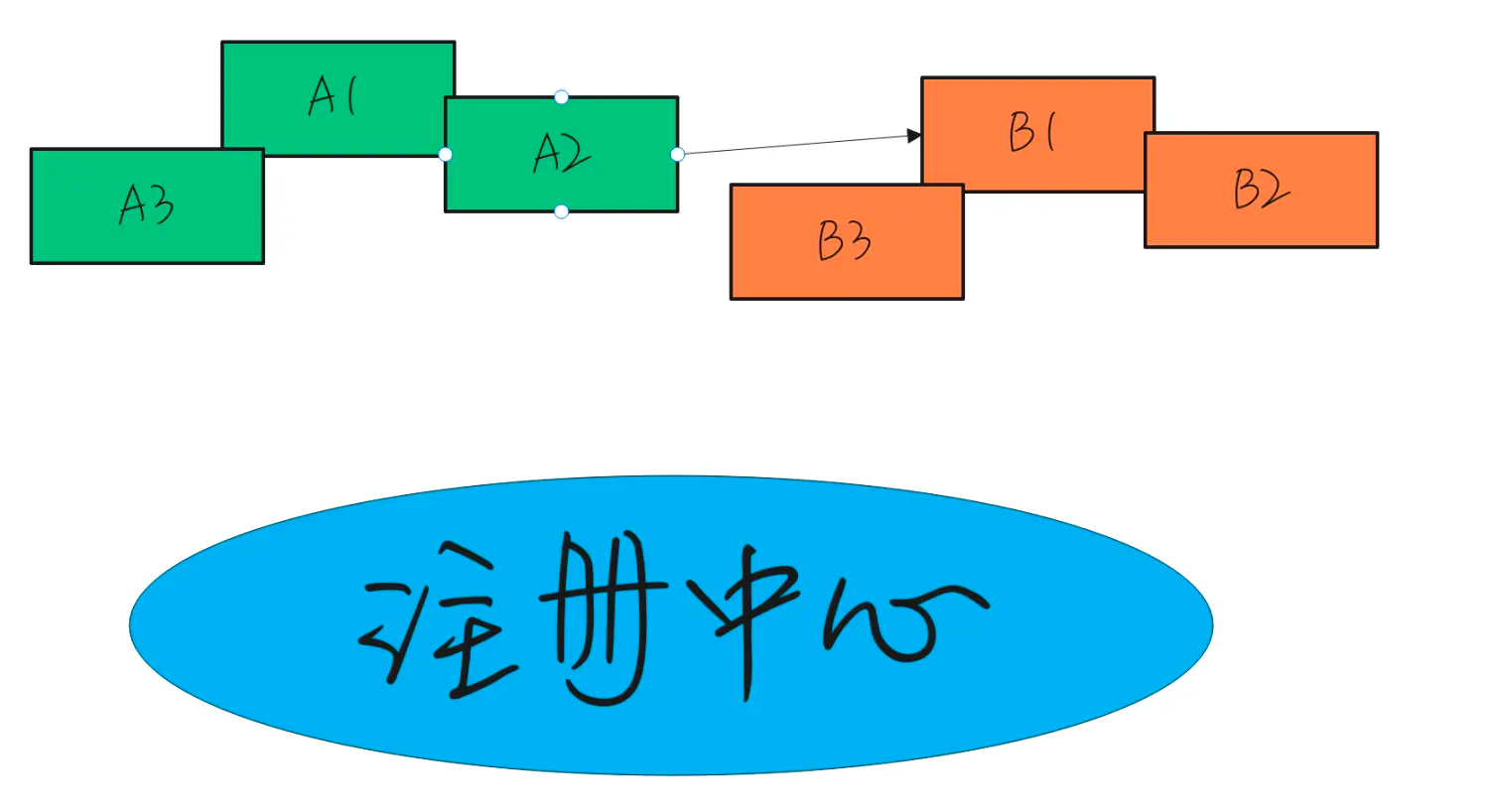
A是一个微服务
B也是一个微服务
蓝色的是常见的注册中心,有zookeeper、eureka等实现。
重试#
重试,在发生可重试错误的时候,重试一次。什么是可重试错误呢?就是重试一次,可能会成功。比如400 BadRequest,那出现这种错误,基本上重试也没有用,就不要浪费我们宝贵的服务器资源了。常见的如servicecomb框架就有重试几次、重试间隔这样的参数。值得一提的是,如果你指望通过重试让升级零呼损,那么你的重试次数,要比你的并行升级实例数大才行。
这也很容易理解,比如A服务调用B服务,B服务有5个实例,B1~B5。这个时候,同时升级B1和B2,A第一次调用了B1,接下来重试,如果运气不好,恰好重试到了B2节点,那么业务还是会失败的。如果防异常故障,就得重试三次才行。
如果是防止单数据中心宕机,重试次数大于同时宕机节点数,这个规则可能就没那么靠谱了。现在,企业部署十几个乃至二十几个微服务实例,已经不是什么新闻了,假设分3数据中心部署,总不能重试接近10次吧,这种时候,最好重试策略和数据中心相关,重试的时候,选择另一个az的实例。目前servicecomb还不支持这种功能。
优雅启停#
优雅停止#
优雅停止,就是说当微服务快要宕机的时候,先从注册中心进行去注册,然后把发送给微服务的消息,处理完毕后,再彻底关闭。这个方式,可以有效地防止升级期间,发送到老节点的呼损。
优雅启动#
优雅启动,当微服务实例,能够处理rpc请求的时候,再将实例自己注册到注册中心。避免请求发进来,实例却无法处理。
这里有一个要求,就是调用方发现被调用方(即A发现B)的注册中心,要和B注册、去注册的注册中心是一个注册中心。有案例是,发现采用k8s发现,注册、去注册却使用微服务引擎,导致呼损。
优劣对比#
可预知节点升级的场景#
重试相对于优雅启停,在预知节点升级的场景没那么优雅,重试次数可能还要和并行升级的节点挂钩,非常的不优雅,且难以维护
不可预知节点升级的场景#
优雅启停无法对不可预知节点升级的场景生效。只有重试能在这个场景发挥作用
其他场景#
重试可以很好地处理网络闪断、长链接中断等场景
总结#
想要实现rpc调用零呼损,重试和优雅启停都不可或缺,都需要实现。