Apache ZooKeeper在华为云IoT服务产品部的使用
前言#
华为云IoT服务产品部致力于提供极简接入、智能化、安全可信等全栈全场景服务和开发、集成、托管、运营等一站式工具服务,助力合作伙伴/客户轻松、快速地构建5G、AI万物互联的场景化物联网解决方案。
架构方面,华为云IoT服务产品部采用云原生微服务架构,ZooKeeper组件在华为云IoT服务产品部的架构中扮演着重要的角色,本文将介绍华为云IoT服务产品部在ZooKeeper的使用。
Apache ZooKeeper 简介#
Apache ZooKeeper是一个分布式、开源的分布式协调服务,由Apache Hadoop的子项目发展而来。作为一个分布式原语的基石服务,几乎所有分布式功能都可以借助ZooKeeper来实现,例如:应用的主备选举,分布式锁,分布式任务分配,缓存通知,甚至是消息队列、配置中心等。
抛开应用场景,讨论某个组件是否适合,并没有绝对正确的答案。尽管Apache ZooKeeper作为消息队列、配置中心时,性能不用想就知道很差。但是,倘若系统里面只有ZooKeeper,应用场景性能要求又不高,那使用ZooKeeper不失为一个好的选择。但ZooKeeper 客户端的编码难度较高,对开发人员的技术水平要求较高,尽量使用一些成熟开源的ZooKeeper客户端、框架,如:Curator、Spring Cloud ZooKeeper等。
Apache ZooKeeper 核心概念#
ZNode#
ZNode是ZooKeeper的数据节点,ZooKeeper的数据模型是树形结构,每个ZNode都可以存储数据,同时可以有多个子节点,每个ZNode都有一个路径标识,类似于文件系统的路径,例如:/iot-service/iot-device/iot-device-1。
Apache ZooKeeper在华为云IoT服务产品部的使用#
支撑系统内关键组件#
很多开源组件都依赖ZooKeeper,如Flink、Ignite、Pulsar等,通过自建和优化ZooKeeper环境,我们能够为这些高级组件提供更加可靠和高效的服务支持,确保服务的平稳运行。
严格分布式锁#
分布式锁是非常常见的需求,相比集群Redis、主备Mysql等,ZooKeeper更容易实现理论上的严格分布式锁。
分布式缓存通知#
ZooKeeper的分布式缓存通知能够帮助我们实现分布式缓存的一致性,例如:我们可以在ZooKeeper上注册一个节点,然后在其他节点上监听这个节点,当这个节点发生变化时,其他节点就能够收到通知,然后更新本地缓存。
这种方式的缺点是,ZooKeeper的性能不高,不适合频繁变更的场景,但是,对于一些不经常变更的配置,这种方式是非常适合的。如果系统中存在消息队列,那么可以使用消息队列来实现分布式缓存通知,这种方式的性能会更好、扩展性更强。
分布式Id生成器#
直接使用ZooKeeper的有序节点#
应用程序可以直接使用ZooKeeper的有序节点来生成分布式Id,但是,这种方式的缺点是,ZooKeeper的性能不高,不适合频繁生成的场景。
1 | import org.apache.zookeeper.CreateMode; |
使用ZooKeeper生成机器号#
应用程序可以使用ZooKeeper生成机器号,然后使用机器号+时间戳+序列号来生成分布式Id。来解决ZooKeeper有序节点性能不高的问题。
1 | import lombok.extern.slf4j.Slf4j; |
微服务注册中心#
相比其他微服务引擎,如阿里云的MSE、Nacos等,已有的Zookeeper集群作为微服务的注册中心,既能满足微服务数量较少时的功能需求,并且更加节约成本
数据库连接均衡#
在此前的架构中,我们采用了一种随机策略来分配微服务与数据库的连接地址。下图展示了这种随机分配可能导致的场景。考虑两个微服务:微服务B和微服务C。尽管微服务C的实例较多,但其对数据库的操作相对较少。相比之下,微服务B在运行期间对数据库的操作更为频繁。这种连接方式可能导致数据库Data2节点的连接数和CPU使用率持续居高,从而成为系统的瓶颈。
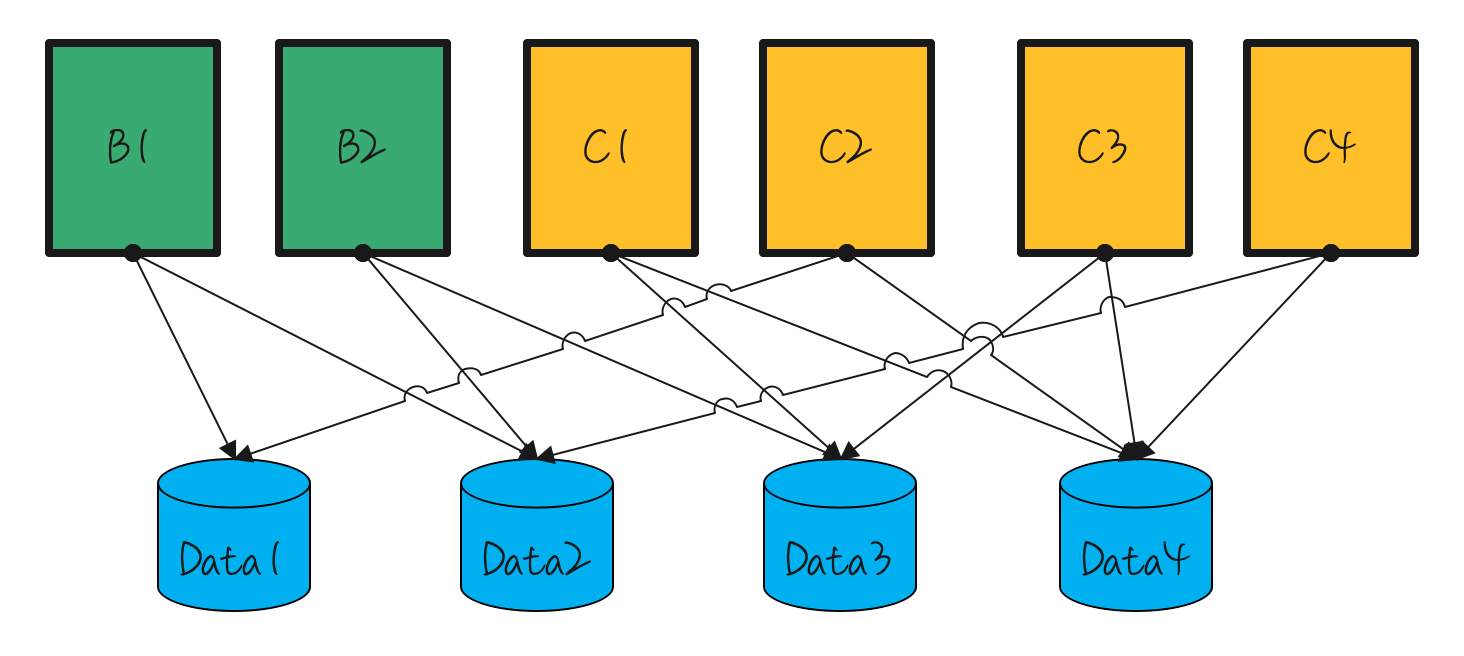
启发于Kafka中的partition分配算法,我们提出了一种新的连接策略。例如,如果微服务B1连接到了Data1和Data2节点,那么微服务B2将连接到Data3和Data4节点。如果存在B3实例,它将再次连接到Data1和Data2节点。对于微服务C1,其连接将从Data1和Data2节点开始。然而,由于微服务的数量与数据库实例数量的两倍(每个微服务建立两个连接)并非总是能整除,这可能导致Data1和Data2节点的负载不均衡。
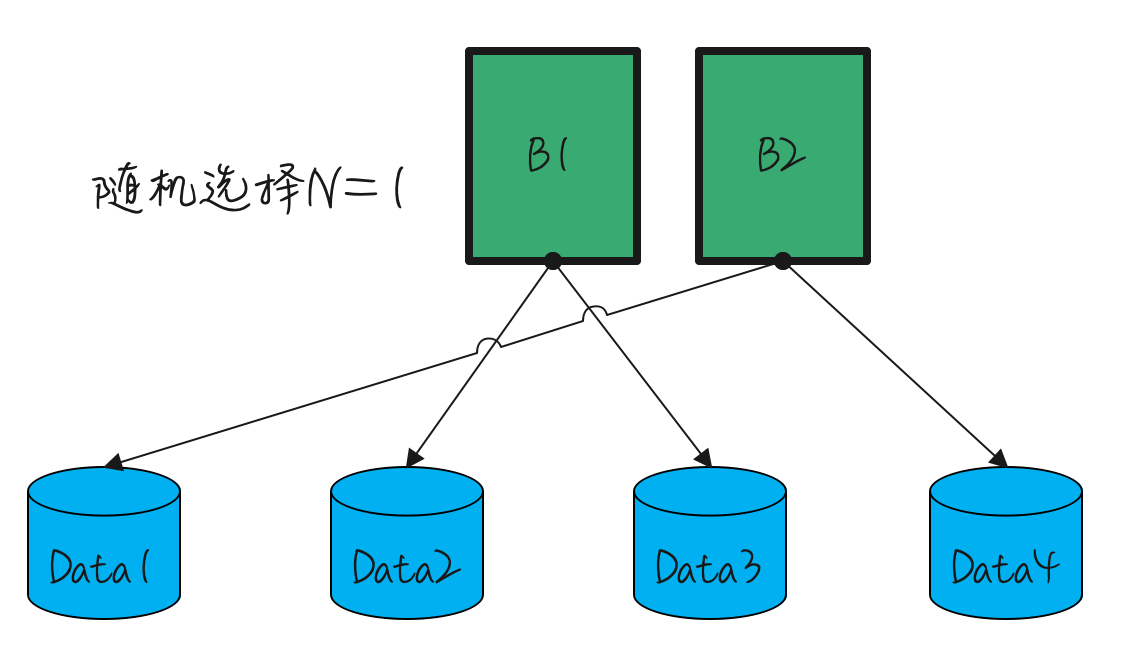
为了解决这一问题,我们进一步优化了策略:第一个微服务实例在选择数据库节点时,将从一个随机起点开始。这种方法旨在确保Data1和Data2节点的负载均衡。具体的分配策略如下图所示。
Apache ZooKeeper在华为云IoT产品部的部署/运维#
服务端部署方式#
我们所有微服务和中间件均采用容器化部署,选择3节点(没有learner)规格。使用statefulset和PVC的模式部署。为什么使用statefulset进行部署?statefulset非常适合用于像Zookeeper这样有持久化存储需求的服务,每个Pod可以和对应的存储资源绑定,保证数据的持久化,同时也简化了部署,如果想使用deploy的部署模式,需要规划、固定每个pod的虚拟机部署。
Zookeeper本身对云硬盘的要求并不高,普通IO,几十G存储就已经能够支撑Zookeeper平稳运行了。Zookeeper本身运行的资源,使用量不是很大,在我们的场景,规格主要取决于Pulsar的topic数量,如果Pulsar的topic不多,那么0.5核、2G内存已经能保证Zookeeper平稳运行了。
客户端连接方式#
借助coredns,客户端使用域名的方式连接Zookeeper,这样可以避免Zookeeper的IP地址变更导致客户端连接失败的问题,如zookeeper-0.zookeeper:2181,zookeeper-1.zookeeper:2181,zookeeper-2.zookeeper:2181
重要监控指标#
readlantency、updatelantency
zk的读写延迟
approximate_data_size
zk中数据的平均大小估计
outstanding_requests
等待
Zookeeper处理的请求数znode_count
Zookeeper当前的znode总数num_alive_connections
Zookeeper当前活跃的连接数
Apache ZooKeeper在华为云IoT产品部的问题#
readiness合理设置#
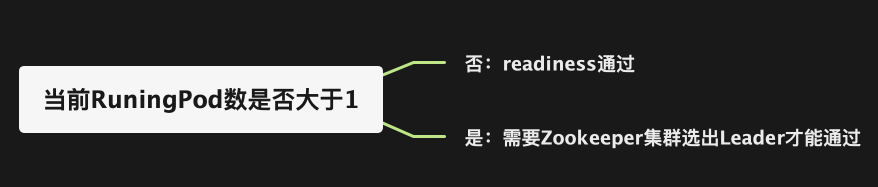
这是碰到的最有趣的问题,readiness接口是k8s判断pod是否正常的依据,那么对于Zookeeper集群来说,最合理的就是,当这个Zookeeper节点加入集群,获得了属于自己的Leader或Follower状态,就算pod正常。可是,当初次部署的时候,只有一个节点可用,该节点一个实例无法完成选举流程,导致无法部署。
综上,我们把readiness的策略修改为:
PS:为了让readiness检查不通过时,Zookeeper集群也能选主成功,需要配置publishNotReadyAddresses为true,示例如下
1 | apiVersion: v1 |
jute.maxbuffer超过上限#
jute.maxbuffer,这个是znode中存储数据大小的上限,在客户端和服务端都需要配置,根据自己在znode上存储的数据合理配置
zookeeper的Prometheus全0监听#
不满足网络监听最小可见原则。修改策略,添加一个可配置参数来配置监听的IP metricsProvider.httpHost,PR已合入,见 https://github.com/apache/zookeeper/pull/1574/files
客户端版本号过低,域名无法及时刷新#
客户端使用域名进行连接,但在客户端版本号过低的情况下,客户端并不会刷新新的ip,还是会用旧的ip尝试连接。升级客户端版本号到curator-4.3.0以上、zookeeper-3.6.2以上版本后解决。
总结#
本文详细介绍了华为云IoT服务产品部如何使用Apache ZooKeeper来优化其云原生微服务架构。ZooKeeper作为分布式协调服务,在华为云IoT服务中发挥了重要作用,用于主备选举、分布式锁、任务分配和缓存通知等。文中还讨论了ZooKeeper在分布式ID生成、微服务注册中心、数据库连接均衡等方面的应用。此外,文章还覆盖了ZooKeeper在华为云IoT产品部的部署、运维策略和所遇到的挑战,包括容器化部署、监控指标和配置问题。